
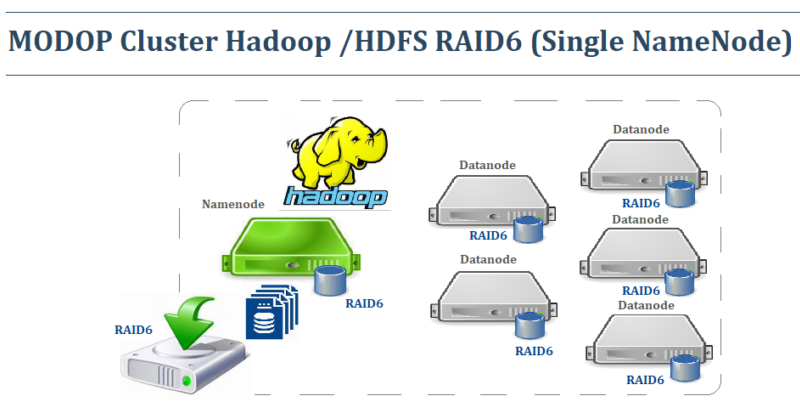
MODOP – Mise en place d’un cluster Hadoop – HDFS (Hadoop Distributed File System) utilisé essentiellement par les applications BIG Data de HADOOP. Il permet l’agrégation de plusieurs volumes disques afin de gérer et de stocker des données volumineuses. Hadoop est un framework open source très résilient à la perte de nœuds Data. Toutes données sont transférées et répliquées rapidement entre les nœuds assurant une grande tolérance de panne. HDFS est un composant clé de nombreux systèmes Hadoop dans l’analyse BIG Data
Continuer la lectureMois : juin 2023

MODOP Cluster Hadoop – Connect Client – Partie 2
MODOP – Connexion d’un Client Linux sur un cluster Hadoop – HDFS (Hadoop Distributed File System). Cette simple connexion permet de réaliser des interactions entre ClientCluster sur l’agrégation des disques du cluster. Toutes données inscrites via le client sont répliquées sur tous les Datanodes à travers le node Manager.
Continuer la lecture
MODOP – Ajout DataNode sur le Custer Hadoop – Partie 3
MODOP – Ajout d’une machine DataNode supplémentaire au cluster Hadoop afin d’augmenter l’agrégation et étendre le volume du disque HDFS sur le Cluster. Il permet aussi d’étendre le nombre de réplication afin d’augmenter la résilience et la persistance des données stockées. Hadoop HDFS est facilement scalable et autorise l’augmentation de grappe disques sur un cluster tout en certifiant l’intégrités des données blocs.
Continuer la lecture