
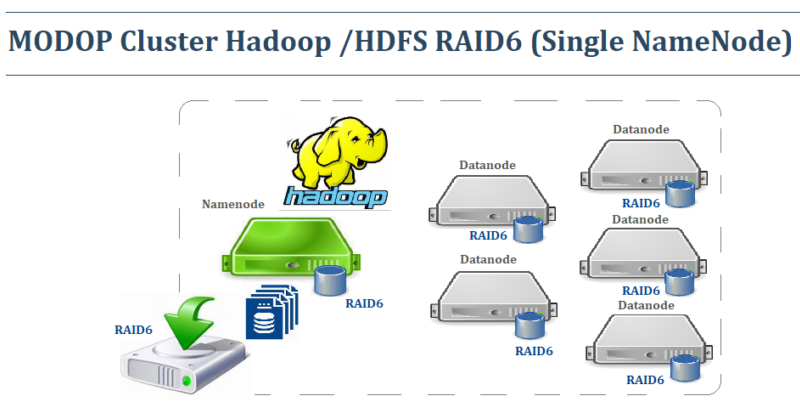
MODOP – Mise en place d’un cluster Hadoop – HDFS (Hadoop Distributed File System) utilisé essentiellement par les applications BIG Data de HADOOP. Il permet l’agrégation de plusieurs volumes disques afin de gérer et de stocker des données volumineuses. Hadoop est un framework open source très résilient à la perte de nœuds Data. Toutes données sont transférées et répliquées rapidement entre les nœuds assurant une grande tolérance de panne. HDFS est un composant clé de nombreux systèmes Hadoop dans l’analyse BIG Data
Continuer la lectureCatégorie : Fichiers Distribué
MODOP – fichiers distribué

MODOP Cluster Hadoop – Connect Client – Partie 2
MODOP – Connexion d’un Client Linux sur un cluster Hadoop – HDFS (Hadoop Distributed File System). Cette simple connexion permet de réaliser des interactions entre ClientCluster sur l’agrégation des disques du cluster. Toutes données inscrites via le client sont répliquées sur tous les Datanodes à travers le node Manager.
Continuer la lecture
MODOP – Ajout DataNode sur le Custer Hadoop – Partie 3
MODOP – Ajout d’une machine DataNode supplémentaire au cluster Hadoop afin d’augmenter l’agrégation et étendre le volume du disque HDFS sur le Cluster. Il permet aussi d’étendre le nombre de réplication afin d’augmenter la résilience et la persistance des données stockées. Hadoop HDFS est facilement scalable et autorise l’augmentation de grappe disques sur un cluster tout en certifiant l’intégrités des données blocs.
Continuer la lecture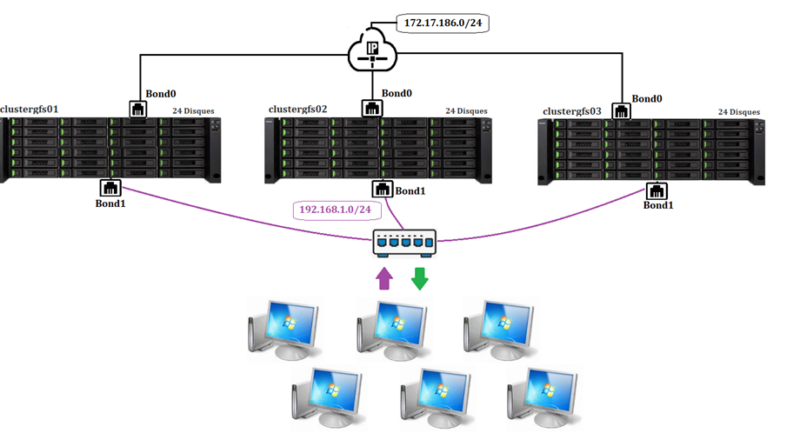
MODOP – Partie 1 – Installation Cluster GlusterFS/Zpool HA
MODOP – Mise en place d’un cluster glusterFS/Zpool/ctdb Haute disponibilité de 3 Baies de disques. Le but est de rendre disponible une ressource de stockage avec pour services CIFS/NFS et cela tout en garantissant une disponibilité la plus résiliente possible. Cette configuration permet la perte de 2x3disques par raidZ2/baies soit 6 disques/baies et 2 baies pour le cluster. Les services CIFS/NFS sont ainsi préservés de toutes pannes éventuelles et cela sans perte de servies et données.
Continuer la lecture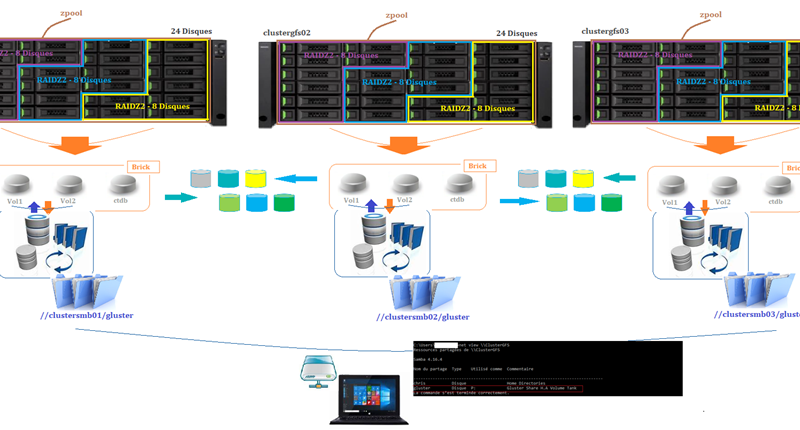
MODOP – Partie 2 – Cluster ZFS/GlusterFS et SAMBA HA
MODOP – Partie 2 – cluster glusterFS/Zpool/ctdb HA via SAMBA/CTDB. Le but est la mise en place du service CIFS via SAMBA afin de mettre à disposition des « share » pour les clients. La partie « failover cluster » et le maintien des « lock samba» sera réalisé par le service ctbd. Celui-ci va permettre de gérer et maintenir les services SMB quel que soit les dysfonctionnements des baies de disques.
Continuer la lecture
MODOP – Partie 3 – Cluster ZFS/GlusterFS et NFS HA
MODOP – Partie 3 – cluster glusterFS/Zpool/ctdb HA via NFS/CTDB. Le but est la mise en place du service NFS afin de mettre à disposition des « share » pour les clients linux. La partie « failover cluster » et le maintien des « lock nfs» sera réalisé par le service ctbd. Celui-ci va permettre de gérer et maintenir les services NFS quel que soit les dysfonctionnements des baies de disques.
Continuer la lecture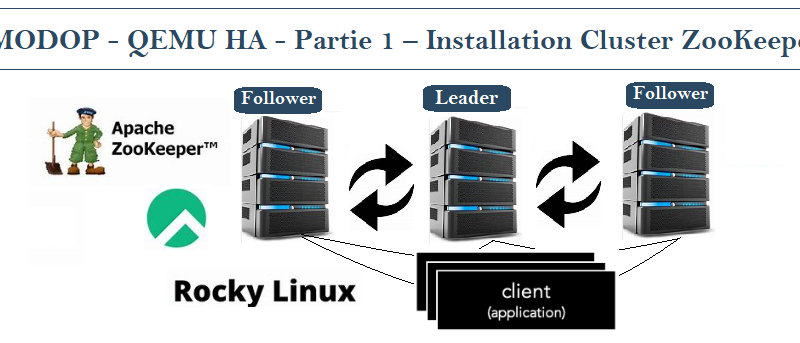
MODOP – QEMU HA – Partie 1 – Installation Cluster ZooKeeper
MODOP – Création d’un cluster Apache ZooKeeper. Celui-ci permet de maintenir des informations de configuration et ainsi fournir à ses clients des services synchronisés et des services de groupes. Dans notre cas il permettra de synchroniser les services de notre cluster sheepdog et éventuellement Qemu. Zookeeper est performant, simplissime à mettre en place mais surtout très scalable et résilient aux pannes. Il est souvent utilisé dans les solutions de cluster de service distribué.
Continuer la lecture
MODOP – QEMU HA – Partie 2 – Installation Cluster sheepdog
MODOP sur l’installation d’un cluster sheepdog délivrant un stockage distribué de type SDS. Ici, le cas d’usage est de stocker en mode bloc les machines virtuelles de Qemu. SheepDog se veut tolérant aux pannes, scalable à souhait et surtout rapide dans sa mise en production. Son avantage, tous les nœuds hébergent les chunks et les métadonnées ce qui rend son architecture très malléable et redimensionnable rapidement. Il faut impérativement le coupler à Zookeer pour gérer les services/messages des membres du cluster Sheepdog.
Continuer la lecture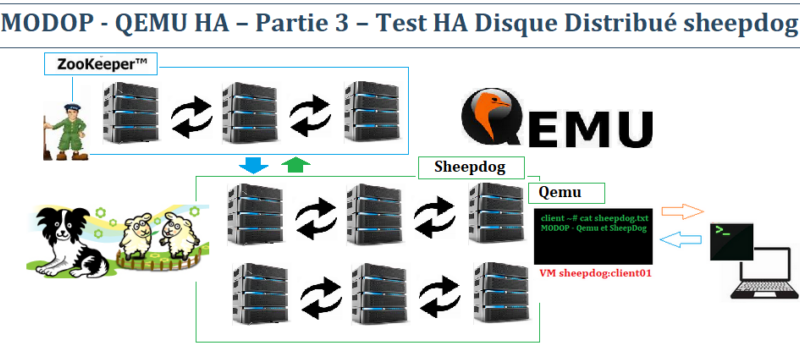
MODOP – QEMU HA – Partie 3 – Test HA Disque Distribué sheepdog
MODOP – Test de résilience des données sur des machines virtuelles QEMU via Sheepdog. Le but est de rendre persistant toutes données inscrites sur une machine virtuelle via l’usage d’un stockage distribué SheepDog. Dans le cas présent, nous allons créer un fichier texte sur une machine VM (Qemu/Sheepdog) du node04 et nous vérifierons sur le node05 que cette donnée est préservée.
Continuer la lecture
MODOP – QEMU HA – Partie 4 – Installation HA Web Machine Sheepdog
MODOP – Test de résilience des services et données sur des machines virtuelles QEMU via Sheepdog/Zookeeper. Le but est de rendre HA « high availability » des applications web, données, DNS, etc via l’usage d’un stockage de type SDS. Dans le cas présent, nous déployons un script Bash Web permettant de redémarrer des machines virtuelles lors de la perte du node « maître » portant les machines VM et la VIP (KeepAllive).
Continuer la lecture