

MODOP sur l’installation et la configuration d’un cluster HAProxy pour assurer la haute disponibilité et l’équilibrage de charge d’un cluster MinIO en mode réplication, il sera composé de deux hosts. HAProxy équilibrera la charge de manière efficace entre les différents hôtes MinIOA, assurant que chaque serveur du répliquas contribue de manière optimale à l’ensemble. Ce processus de mise en place permet de minimiser les points de défaillance unique, d’améliorer les performances globales et de garantir un accès continu aux données, même en cas de panne de l’un des nœuds. HAProxy optimisera l’utilisation des ressources et renforcera la résilience du cluster de réplication (site2) MinIO.
Continuer la lectureÉtiquette : Cluster HA
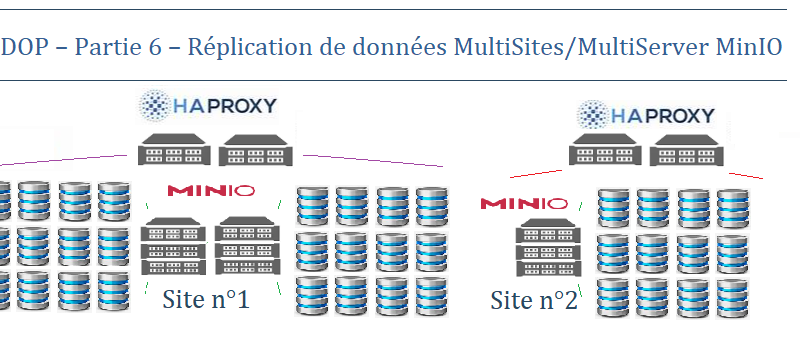
MODOP – Partie 6 – Réplication de donnéess MultiSites/MultiServer MinIO
MODOP sur la démonstration de l’utilisation de deux clusters MinIO en configuration multisite, garantissant une haute disponibilité des données, tout en permettant une résilience et une fiabilité accrues.MinIO en multisite permet d’assurer la haute disponibilité et l’accessibilité continue des données, même en cas de défaillance d’un site.En utilisant deux clusters MinIO en configuration multisite, cela assure une haute disponibilité des données grâce à une répartition géographique et un équilibrage de charge efficace. Cela rend l’infrastructure robuste et résiliente aux pannes, garantissant une continuité des opérations et une sécurité accrue pour tes données.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 1 -Introduction
MODOP sur l’installation d’un cluster SeaweedFS système de fichiers distribué mode block open-source, simple et hautement évolutif conçu pour stocker et servir rapidement des milliards de fichiers. Il partage des similitudes avec d’autres systèmes de fichiers tels que Ceph, GlusterFS et HDFS. Il est constitué de différent type de service tel que des machines Masters , Volumes et Filers. Il fortement évolutif et scalable en fonction des besoins du quotidien.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 2 – Installation 3 nodes Master
MODOP sur la mise en place d’un cluster de 3 Maître SeaweedFS permettant la gestion des Volumes centralisées. Le maître SeaweedFS joue un rôle essentiel dans la gestion des volumes et la localisation des fichiers, contribuant ainsi à la rapidité et à l’efficacité du système de fichiers distribué. SeaweedFS est basés sur le magasin d’objets RADOS (Reliable Autonomic Distributed Object Store) permettant un accès cohérent aux données, au stockage redondant, à la détection des pannes. Il est est conçu pour les systèmes de stockage à l’échelle du pétaoctet en garantissant une cohérence de la données.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 3 – Installation 4 nodes Volumes
MODOP sur la mise en place d’un cluster de 4 Volumes SeaweedFS permettant la gestion des données , la répartition de charge et l’accès rapide aux fichiers. Chaque volumes seaweed de données à une taille de 32Go et peut contenir plusieurs volumes , il va stocker les objets et laisse la gestion des métadonnées aux Masters. L’accès aux fichiers est généralement très rapide, nécessitant souvent une seule opération de lecture de disque. L’ajout de nœud « Volume » est très aisé et facilite grandement la répartition de charge des données rendant le cluster scalable à souhait.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 4 – Installation 4 nodes Filers
MODOP sur la mise en place d’un cluster de 4 Filers SeaweedFS permettant la gestion des répertoires et de la structure des fichiers. Ils stockent les métadonnées associées aux fichiers, telles que les noms, les autorisations et les chemins d’accès. Ils répartissent la charge entre les serveurs de volumes en gérant les métadonnées de manière décentralisée. Cela permet d’éviter une pression excessive sur le maître central et d’améliorer les performances d’accès aux fichiers. les filers permettent un accès rapide aux fichiers.
Continuer la lecture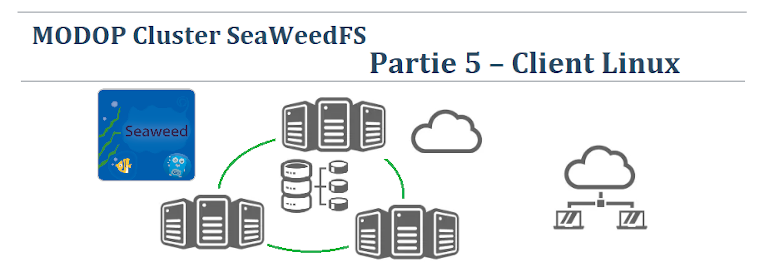
MODOP Cluster SeaWeedFS – Partie 5 – Client Linux
MODOP sur la mise en place d’un client SeaweedFS permettant de se connecter à un serveur de fichiers distribués nommé SeaweedFS. Il va interagir avec le serveur SeaweedFS et effectuer des opérations comme télécharger, envoyer, supprimer ou lister des fichiers. SeaweedFS est inspiré par l’algorithme Facebook pour gérer efficacement de grandes quantités de données dans le cloud.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 6 – Ajout 2 nodes Master
MODOP sur l’ajout de deux master SeaweedFS afin d’augmenter la performance et la fiabilité du système de fichiers distribués. Les master SeaweedFS sont responsable de gérer les volumes sur les serveurs de volumes, de répartir la charge entre eux, de détecter les pannes et de lancer les réparations. Les master SeaweedFS utilisent un algorithme de consensus appelé Raft pour maintenir une cohérence forte entre les répliques du master.En général, plus il y a de répliques du master, plus le système est résilient aux pannes, mais plus le temps de réponse est long.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 7 – Ajout 1 node Volume
MODOP sur l’ajout d’un node Volume SeaweedFS permettant d’augmenter la taille de stockage du cluster SeaweeFS.En général, plus il y a de volumes, plus le système peut stocker de données, mais plus le master SeaweedFS doit gérer de métadonnées. Plus la taille des volumes est petite, plus le système peut répartir la charge entre les serveurs de volumes, mais plus le système consomme de l’espace disque pour les métadonnées. Plus il y a de serveurs de volumes, plus le système peut augmenter sa capacité de stockage et sa tolérance aux pannes, mais plus le master SeaweedFS doit communiquer avec eux. Plus il y a de requêtes, plus le système doit traiter de messages et synchroniser son état avec le master SeaweedFS. Plus le débit du réseau est élevé, plus le système peut transférer rapidement les données entre les serveurs de volumes et le master SeaweedFS
Continuer la lecture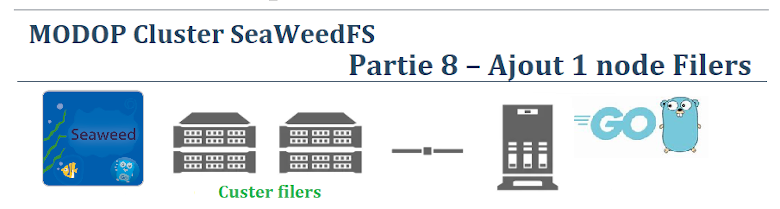
MODOP Cluster SeaWeedFS – Partie 8 – Ajout 1 node Filers
MODOP sur la mise en place d’un client Filer permettant d’accéder aux fichiers stockés sur le système via une interface POSIX, WebDAV, S3, FUSE ou Hadoop.En général, plus il y a de filers, plus le système peut supporter de requêtes concurrentes, mais plus le système doit synchroniser les données entre les filers et la base de données. Plus le type de base de données est performant, plus le système peut gérer de fichiers et de métadonnées, mais plus le système consomme de ressources. Plus il y a de fichiers, plus le système doit stocker et indexer de métadonnées, mais plus le système offre de capacité de stockage. Plus il y a de requêtes, plus le système doit traiter de messages et transférer des données entre les filers, la base de données et le master SeaweedFS. Plus le débit du réseau est élevé, plus le système peut communiquer rapidement entre les filers, la base de données et le master SeaweedFS
Continuer la lecture