
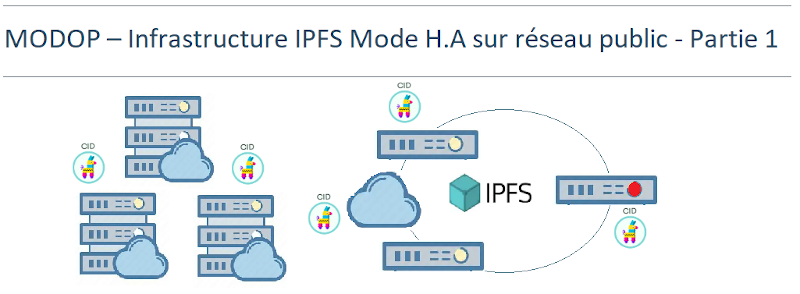
MODOP sur l’installation d’une infrastructure robuste et distribuée pour le stockage et la diffusion de fichiers à l’échelle mondiale. Elle repose sur le protocole IPFS (InterPlanetary File System), basé sur une architecture P2P comprenant un nœud leader responsable de la gestion des pins, accompagné de deux peers assurant la réplication des données. L’ensemble des machines est configuré en RAID1 afin de garantir une redondance locale des données sur chaque nœud. Connectées via le réseau public (Internet), elles offrent une accessibilité universelle et permettent une mise à l’échelle mondiale du partage de contenu. Grâce à l’adressage par CID (Content Identifier) et à la nature décentralisée du protocole IPFS, si l’un des nœuds devient indisponible, les autres peuvent continuer à servir les fichiers, assurant ainsi une haute disponibilité .L’architecture distribuée, couplée à une répartition géographique des peers, optimise la latence et la performance du système pour les utilisateurs finaux. Ce type d’infrastructure est particulièrement adapté aux cas d’usage nécessitant scalabilité, résilience et disponibilité continue, tels que le stockage de données sensibles, l’hébergement web décentralisé ou les applications Web.
Continuer la lectureÉtiquette : Serveur
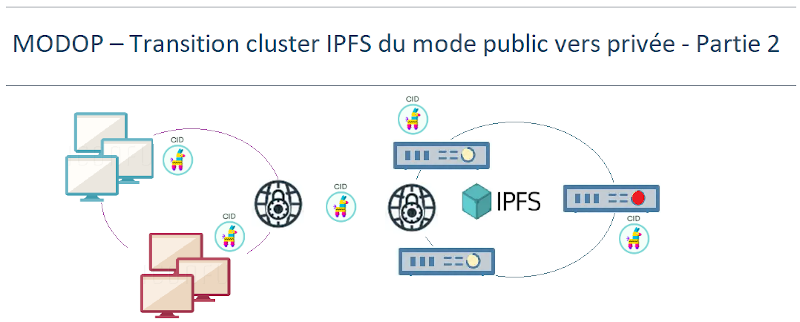
MODOP – Transition d’un cluster IPFS du mode public vers une architecture privée – Partie 2
Ce MODOP décrit la migration d’une infrastructure IPFS, initialement déployée en mode public, vers un environnement privé et sécurisé. La nouvelle architecture repose sur un réseau P2P fermé, tout en conservant sa structure : un nœud leader chargé d’orchestrer les pins, accompagné de deux peers assurant la réplication des données. Dans ce cadre privé, seuls les nœuds disposant de la clé swarm partagée peuvent rejoindre le réseau, garantissant la confidentialité des échanges ainsi que le contrôle d’accès. Cette approche renforce la sécurité tout en préservant les caractéristiques essentielles de l’infrastructure, notamment une haute disponibilité , même en cas de défaillance d’un nœud ,et une scalabilité maintenue, permettant l’ajout de nouveaux pairs sans exposition au réseau public.
Continuer la lecture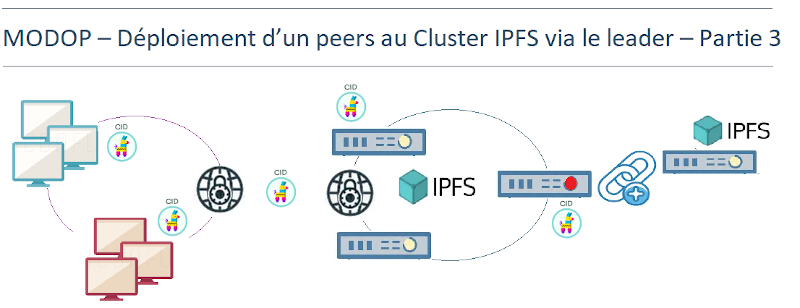
MODOP – Déploiement d’un peers au Cluster via le leader – Partie 3
MODOP sur l’intégration d’un nouveau nœud peer dans un cluster IPFS privé, sans interruption du service. L’ajout de ce nœud permet d’étendre la capacité de stockage, de renforcer la haute disponibilité et la résilience en cas de panne, ainsi que d’accroître la redondance des données grâce à la réplication P2P. Cette opération est réalisée sans perturber les nœuds existants. Le nouveau nœud s’intègre de manière transparente au sein du cluster.
Continuer la lecture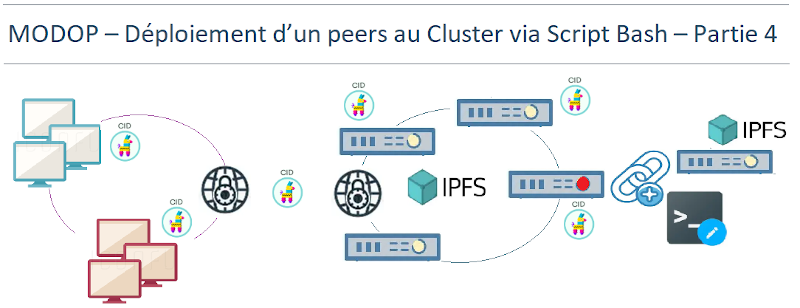
MODOP – Cluster IPFS RAID1 – déploiement d’un peers au Cluster via Script Bash – Partie 4
Ce MODOP décrit l’évolution du cluster IPFS privé par l’ajout d’un nouveau nœud peer, réalisé à l’aide d’un script Bash automatisant l’ensemble des étapes techniques. Cette approche permet une intégration rapide, fiable, et sans interruption de service pour les nœuds déjà actifs. L’objectif de l’automatisation est accélérer le déploiement de nouveaux nœuds, réduire les risques d’erreurs liés aux manipulations manuelles en ligne de commande (CLI),simplifier l’extension du cluster et garantir la confidentialité des échanges et la stabilité du réseau. Le script assure une intégration transparente du nouveau nœud dans un contexte industriel, avec une logique de scalabilité maîtrisée. Cette méthode facilite l’industrialisation du processus tout en respectant les exigences de sécurité, de redondance, et de haute disponibilité du système.
Continuer la lecture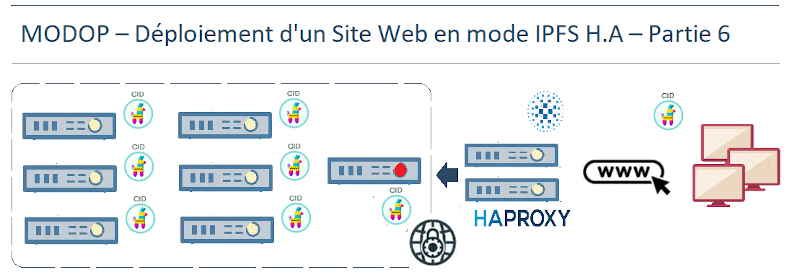
MODOP – Cluster IPFS RAID1 – déploiement Site Web en mode H.A – Partie 6
Ce MODOP présente le déploiement d’une solution Web P2P hautement disponible, accessible via une IP virtuelle (VIP), en s’appuyant sur l’infrastructure IPFS existante. L’enjeu consiste à ajouter deux nouvelles machines destinées à assurer la redondance et la gestion de charge pour l’accès aux données distribuées sur les peers. Deux services essentiels sont installés : KeepAlive, pour garantir la continuité du service Web en cas de défaillance d’un nœud et HAProxy, pour gérer l’équilibrage de charge et la distribution du trafic client vers les nœuds disponibles. Cette infrastructure Web P2P permettra une Une accessibilité continue du site hébergé via la VIP, Un hébergement distribué des données Web sur IPFS, Une résilience optimale grâce à KeepAlive, HAProxy et IPFS et Une scalabilité fluide, avec la possibilité d’extension sans interruption du service
Continuer la lecture
MODOP – Partie 1 – Installation Cluster 6 hosts minIO
MODOP – Mise en place de l’installation et la configuration d’un cluster MinIO composé de six hôtes, chacun équipé de quatre disques. MinIO est une solution de stockage d’objets conçue pour fournir une plateforme de stockage hautement évolutive, fiable et compatible avec l’API Amazon S3. C’est particulièrement utile dans les environnements où les besoins en stockage sont importants, comme les entreprises qui manipulent de grandes quantités de données. MinIO est privilégié pour sa sécurité robuste, incluant le chiffrement des données au repos et en transit, et ses performances élevées. Il est également apprécié pour sa capacité à être déployé sur divers environnements, qu’il s’agisse de serveurs locaux, de conteneurs Docker, ou de plateformes cloud. En résumé, MinIO offre une solution flexible et sécurisée pour gérer et protéger des volumes massifs de données.
Continuer la lecture
MODOP – Partie 2 – HA Proxy pour le Cluster minIO
MODOP sur l’installation et la configuration d’un cluster HAProxy pour garantir la haute disponibilité et l’équilibrage de charge dans un cluster MinIO. HAProxy va répartir le trafic entre tes différents serveurs MinIO, s’assurant ainsi que la charge est équilibrée et qu’il n’y a pas de point de défaillance. Il va permettre de répartir le trafic entre les différents serveurs MinIO pour éviter les surcharges, assurer la continuité du service en cas de panne d’un serveur, et optimiser les performances
Continuer la lecture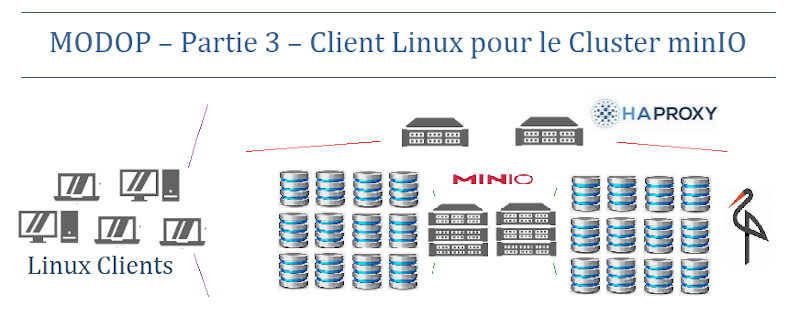
MODOP – Partie 3 – Client Linux – Cluster minIO
MODOP sur l’installation et la configuration d’un client Linux pour interagir efficacement avec un cluster MinIO. Il permet une gestion optimisée et sécurisée des ressources de stockage. Le client facilite les tâches quotidiennes telles que la surveillance et l’administration des données réparties. En outre, il assure l’accessibilité et la manipulation sécurisée des données grâce au chiffrement et à l’authentification intégrés de MinIO.
Continuer la lecture
MODOP – Partie 4 – Cluster de Réplication MinIO
MODOP sur l’installation et configuration un cluster de réplication MinIO, garantissant la haute disponibilité et l’efficacité dans la gestion de grandes quantités de données. Ce deuxième cluster de réplication MinIO est conçu pour assurer une haute disponibilité des données entre deux sites géographiquement distants. En répartissant les données sur plusieurs emplacements, cette configuration garantit que même en cas de défaillance d’un site, les données restent accessibles et intactes. Cette architecture renforce la résilience et la robustesse de l’infrastructure, minimisant les temps d’arrêt et assurant une continuité des opérations.
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 4 – Installation 4 nodes Filers
MODOP sur la mise en place d’un cluster de 4 Filers SeaweedFS permettant la gestion des répertoires et de la structure des fichiers. Ils stockent les métadonnées associées aux fichiers, telles que les noms, les autorisations et les chemins d’accès. Ils répartissent la charge entre les serveurs de volumes en gérant les métadonnées de manière décentralisée. Cela permet d’éviter une pression excessive sur le maître central et d’améliorer les performances d’accès aux fichiers. les filers permettent un accès rapide aux fichiers.
Continuer la lecture