

MODOP sur l’ajout de deux master SeaweedFS afin d’augmenter la performance et la fiabilité du système de fichiers distribués. Les master SeaweedFS sont responsable de gérer les volumes sur les serveurs de volumes, de répartir la charge entre eux, de détecter les pannes et de lancer les réparations. Les master SeaweedFS utilisent un algorithme de consensus appelé Raft pour maintenir une cohérence forte entre les répliques du master.En général, plus il y a de répliques du master, plus le système est résilient aux pannes, mais plus le temps de réponse est long.
Continuer la lectureÉtiquette : Serveur

MODOP Cluster SeaWeedFS – Partie 7 – Ajout 1 node Volume
MODOP sur l’ajout d’un node Volume SeaweedFS permettant d’augmenter la taille de stockage du cluster SeaweeFS.En général, plus il y a de volumes, plus le système peut stocker de données, mais plus le master SeaweedFS doit gérer de métadonnées. Plus la taille des volumes est petite, plus le système peut répartir la charge entre les serveurs de volumes, mais plus le système consomme de l’espace disque pour les métadonnées. Plus il y a de serveurs de volumes, plus le système peut augmenter sa capacité de stockage et sa tolérance aux pannes, mais plus le master SeaweedFS doit communiquer avec eux. Plus il y a de requêtes, plus le système doit traiter de messages et synchroniser son état avec le master SeaweedFS. Plus le débit du réseau est élevé, plus le système peut transférer rapidement les données entre les serveurs de volumes et le master SeaweedFS
Continuer la lecture
MODOP Cluster SeaWeedFS – Partie 8 – Ajout 1 node Filers
MODOP sur la mise en place d’un client Filer permettant d’accéder aux fichiers stockés sur le système via une interface POSIX, WebDAV, S3, FUSE ou Hadoop.En général, plus il y a de filers, plus le système peut supporter de requêtes concurrentes, mais plus le système doit synchroniser les données entre les filers et la base de données. Plus le type de base de données est performant, plus le système peut gérer de fichiers et de métadonnées, mais plus le système consomme de ressources. Plus il y a de fichiers, plus le système doit stocker et indexer de métadonnées, mais plus le système offre de capacité de stockage. Plus il y a de requêtes, plus le système doit traiter de messages et transférer des données entre les filers, la base de données et le master SeaweedFS. Plus le débit du réseau est élevé, plus le système peut communiquer rapidement entre les filers, la base de données et le master SeaweedFS
Continuer la lecture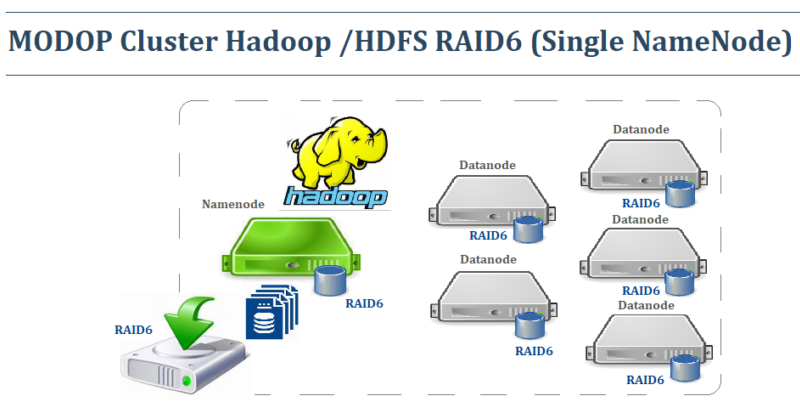
MODOP Cluster Hadoop /HDFS RAID6 (Single NameNode) – Partie 1
MODOP – Mise en place d’un cluster Hadoop – HDFS (Hadoop Distributed File System) utilisé essentiellement par les applications BIG Data de HADOOP. Il permet l’agrégation de plusieurs volumes disques afin de gérer et de stocker des données volumineuses. Hadoop est un framework open source très résilient à la perte de nœuds Data. Toutes données sont transférées et répliquées rapidement entre les nœuds assurant une grande tolérance de panne. HDFS est un composant clé de nombreux systèmes Hadoop dans l’analyse BIG Data
Continuer la lecture
MODOP Cluster Hadoop – Connect Client – Partie 2
MODOP – Connexion d’un Client Linux sur un cluster Hadoop – HDFS (Hadoop Distributed File System). Cette simple connexion permet de réaliser des interactions entre ClientCluster sur l’agrégation des disques du cluster. Toutes données inscrites via le client sont répliquées sur tous les Datanodes à travers le node Manager.
Continuer la lecture
MODOP – Ajout DataNode sur le Custer Hadoop – Partie 3
MODOP – Ajout d’une machine DataNode supplémentaire au cluster Hadoop afin d’augmenter l’agrégation et étendre le volume du disque HDFS sur le Cluster. Il permet aussi d’étendre le nombre de réplication afin d’augmenter la résilience et la persistance des données stockées. Hadoop HDFS est facilement scalable et autorise l’augmentation de grappe disques sur un cluster tout en certifiant l’intégrités des données blocs.
Continuer la lecture
MODOP – Partie 2 – BASH Update to OpenSSH 9.3p1
MODOP sur la mise à jour de OpenSSh automatisée à l’aide d’un script bash sur des machines Centos/RockyLinux/Almalinux 7 et 8.
le script va récupérer les sources et dépendances et générer des RPM qui seront par la suite installées automatiquement.
MODOP – YubiKey – Cient SSH – GitHub
MODOP – Mise en place d’une connexion SSH entre un client et l’application Github via YubiKey. Depuis fin 2021 , les connexions à vos repository sur Git doivent se réaliser via des clefs SSH. Dans le cas présent , nous allons mettre en place une solution de connexion SSH à l’aide d’un second facteur d’authentification « physique » afin d’augmenter la sécurité. Tous vos push seront réalisés avec une clef SSH + Clef YubiKey.
Continuer la lecture
MODOP – Connexion SSH YubiKey – Linux Machine
MODOP – Mise en place d’une connexion SSH entre un client et un Serveur via une clef Yubikey .Cette connexion permet de renforcer la connexion sur des machines serveur et cela à l’aide d’un second facteur d’authentification « physique » prouvant son identité. Elle permet ainsi de s’affranchir de la mémorisation de mot de passe compliqués.
Continuer la lecture
MODOP – Partie 1 – PostgreSQL HA – Installation du Cluster ETCD
MODOP sur la mise en place d’un cluster ETCD pour gérer la coordination de plusieurs nœuds d’un cluster postgreSQL en haute disponibilité avec l’aide de Patroni . Il va permettre le stockage de la configuration et des informations de fonctionnement du cluster (nœuds, config, comptes, les rôles, etc.).
Il est assimilé à une base de données distribuée de type clé-valeur.