

MODOP – Connexion d’un Client Linux sur un cluster Hadoop – HDFS (Hadoop Distributed File System). Cette simple connexion permet de réaliser des interactions entre ClientCluster sur l’agrégation des disques du cluster. Toutes données inscrites via le client sont répliquées sur tous les Datanodes à travers le node Manager.
Continuer la lectureÉtiquette : Système

MODOP – Ajout DataNode sur le Custer Hadoop – Partie 3
MODOP – Ajout d’une machine DataNode supplémentaire au cluster Hadoop afin d’augmenter l’agrégation et étendre le volume du disque HDFS sur le Cluster. Il permet aussi d’étendre le nombre de réplication afin d’augmenter la résilience et la persistance des données stockées. Hadoop HDFS est facilement scalable et autorise l’augmentation de grappe disques sur un cluster tout en certifiant l’intégrités des données blocs.
Continuer la lecture
MODOP – Partie 1 – Update OpenSSH To 9.3p1
MODOP sur la mise à jour de OpenSSH pour des machines Centos/RockyLinux/Almalinux 7 et 8. OpenSSH permet la connexion sécurisée via les service ssh , sftp et ssh-agent. Il regroupe plusieurs binaires et notamment ssh-keygen et ssh-copy-id.Son but est la connexion distante sécurisée en offrant de nombreuses capacités en chiffrement et authentification. Il est le service incontournable pour vos connexions entre client/client ou client/serveur.
Continuer la lecture
MODOP – Partie 2 – BASH Update to OpenSSH 9.3p1
MODOP sur la mise à jour de OpenSSh automatisée à l’aide d’un script bash sur des machines Centos/RockyLinux/Almalinux 7 et 8.
le script va récupérer les sources et dépendances et générer des RPM qui seront par la suite installées automatiquement.
MODOP – YubiKey – Cient SSH – GitHub
MODOP – Mise en place d’une connexion SSH entre un client et l’application Github via YubiKey. Depuis fin 2021 , les connexions à vos repository sur Git doivent se réaliser via des clefs SSH. Dans le cas présent , nous allons mettre en place une solution de connexion SSH à l’aide d’un second facteur d’authentification « physique » afin d’augmenter la sécurité. Tous vos push seront réalisés avec une clef SSH + Clef YubiKey.
Continuer la lecture
MODOP – Connexion SSH YubiKey – Linux Machine
MODOP – Mise en place d’une connexion SSH entre un client et un Serveur via une clef Yubikey .Cette connexion permet de renforcer la connexion sur des machines serveur et cela à l’aide d’un second facteur d’authentification « physique » prouvant son identité. Elle permet ainsi de s’affranchir de la mémorisation de mot de passe compliqués.
Continuer la lecture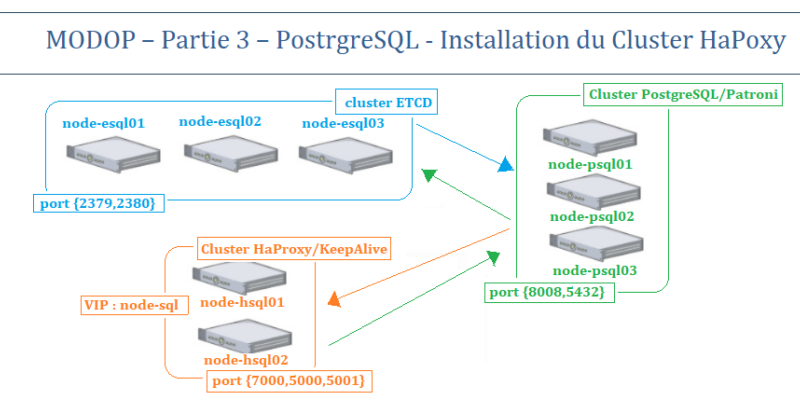
MODOP – Partie 3 – PostrgreSQL – Installation du Cluster HaPoxy
MODOP sur la mise en place de HA Proxy/KeepAlived pour un cluster de service Haute disponibilité de base de données postgreSQL. Le service KeepAlived va permettre de gérer la mise à disposition d’une « Virual IP » et la bascule de celle-ci lors de la perte d’un nœud KeepAlived/HA Proxy. Le service HAProxy va permettre de faire du « Balancing » de flux réseau de requêtes SQL Read/Write sur les nœuds du cluster postgreSQL.
Continuer la lecture
MODOP – Partie 4 – PostgreSQL HA – Connexion sql via client Linux
MODOP sur un client LINUX se connectant à un cluster Haute Disponibilité de service PostgreSQL via HaProxy . Le client va générer deux types de requêtes SQL , L’une en « Read – SELECT » sur le port 5000 et l’autre « Write – UPDATE/INSERT» sur le port 5001. HaProxy orientera les deux types de requête en fonction des ports TCP utilisés. SQL « READ » vers les réplicas du cluster PostrgreSQL . SQL « WRITE » vers le(s) master du cluster PostrgreSQL .
Continuer la lecture
MODOP – Partie 6 – PostgreSQL HA – Grafana/Prometheus : Cluster PostgreSQL
MODOP sur la mise en place du monitoring d’un cluster HA postgreSQL via le couple de service Grafana/Prometheus. Les « metrics » seront récupérés via un « exporter » sur le port 9187 et « scrappé » par le service Prometheus qui les traitera dans leurs temporalités. Le service web Grafana affichera les données sous formes de Widget facilitant la compréhension des données du Cluster postgreSQL
Continuer la lecture
MODOP – Installation d’un Cluster etcd
MODOP – Mise ne place d’un cluster ETCD permettant le stockage et la distribution de données-clé-valeur à destination de cluster machines. Cela peut être assimilé à une base de données distribuée stockant les configurations systèmes, la découverte de services, de comptes, la coordination et la gestion des Hôtes d’un cluster, etc. Il est souvent utilisé dans le cas de cluster de machine comme kubernetes , MySQL , PostgreSQL, etc.
Continuer la lecture